![]()
Best Databricks Associate-Developer-Apache-Spark-3.5 Exam Practice Material Updated on Mar 13, 2026
New Associate-Developer-Apache-Spark-3.5 Actual Exam Dumps, Databricks Practice Test
NEW QUESTION # 51
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0.
The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?
A)
B)
C)
D)
- A. result_df = prices_df \
.withColumn("valid_price", F.when(F.col("spot_price") > F.lit(min_price), 1).otherwise(0)) - B. result_df = prices_df \
.agg(F.count_if(F.col("spot_price") >= F.lit(min_price))) - C. result_df = prices_df \
.agg(F.min("spot_price"), F.max("spot_price")) - D. result_df = prices_df \
.agg(F.count("spot_price").alias("spot_price")) \
.filter(F.col("spot_price") > F.lit("min_price"))
Answer: B
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
The correct answer isBbecause it uses the new function count_if, introduced in Spark 3.5.0, which simplifies conditional counting within aggregations.
* F.count_if(condition) counts the number of rows that meet the specified boolean condition.
* In this example, it directly counts how many times spot_price >= min_price evaluates to true, replacing the older verbose combination of when/otherwise and filtering or summing.
Official Spark 3.5.0 documentation notes the addition of count_if to simplify this kind of logic:
"Added count_if aggregate function to count only the rows where a boolean condition holds (SPARK-
43773)."
Why other options are incorrect or outdated:
* Auses a legacy-style method of adding a flag column (when().otherwise()), which is verbose compared to count_if.
* Cperforms a simple min/max aggregation-useful but unrelated to conditional array operations or the updated functionality.
* Dincorrectly applies .filter() after .agg() which will cause an error, and misuses string "min_price" rather than the variable.
Therefore,Bis the only option leveraging new functionality from Spark 3.5.0 correctly and efficiently.
NEW QUESTION # 52
A data engineer noticed improved performance after upgrading from Spark 3.0 to Spark 3.5. The engineer found that Adaptive Query Execution (AQE) was enabled.
Which operation is AQE implementing to improve performance?
- A. Collecting persistent table statistics and storing them in the metastore for future use
- B. Optimizing the layout of Delta files on disk
- C. Improving the performance of single-stage Spark jobs
- D. Dynamically switching join strategies
Answer: D
Explanation:
Comprehensive and Detailed Explanation:
Adaptive Query Execution (AQE) is a Spark 3.x feature that dynamically optimizes query plans at runtime.
One of its core features is:
Dynamically switching join strategies (e.g., from sort-merge to broadcast) based on runtime statistics.
Other AQE capabilities include:
Coalescing shuffle partitions
Skew join handling
Option A is correct.
Option B refers to statistics collection, which is not AQE's primary function.
Option C is too broad and not AQE-specific.
Option D refers to Delta Lake optimizations, unrelated to AQE.
Final Answer: A
NEW QUESTION # 53
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?
- A. Add the option wholetext=False to the text() function.
- B. Add the option lineSep=", " to the text() function.
- C. Add the option wholetext to the text() function.
- D. Add the option lineSep to the text() function.
Answer: C
Explanation:
By default, the spark.read.text() method reads a text file one line per record. This means that each line in a text file becomes one row in the resulting DataFrame.
To read each file as a single record, Apache Spark provides the option wholetext, which, when set to True, causes Spark to treat the entire file contents as one single string per row.
Correct usage:
df = spark.read.option("wholetext", True).text(txt_path)
This way, each record in the DataFrame will contain the full content of one file instead of one line per record.
To also include the file path, the function input_file_name() can be used to create an additional column that stores the complete path of the file being read:
from pyspark.sql.functions import input_file_name
df = spark.read.option("wholetext", True).text(txt_path) \
.withColumn("file_path", input_file_name())
This approach satisfies both requirements from the question:
Each record holds the entire contents of a file.
Each record also contains the file path from which the text was read.
Why the other options are incorrect:
B or D (lineSep) - The lineSep option only defines the delimiter between lines. It does not combine the entire file content into a single record.
C (wholetext=False) - This is the default behavior, which still reads one record per line rather than per file.
Reference (Databricks Apache Spark 3.5 - Python / Study Guide):
PySpark API Reference: DataFrameReader.text - describes the wholetext option.
PySpark Functions: input_file_name() - adds a column with the source file path.
Databricks Certified Associate Developer for Apache Spark Exam Guide (June 2025): Section "Using Spark DataFrame APIs" - covers reading files and handling DataFrames.
NEW QUESTION # 54
A data engineer needs to write a DataFramedfto a Parquet file, partitioned by the columncountry, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
- A. df.write.mode("overwrite").partitionBy("country").parquet("/data/output")
- B. df.write.mode("append").partitionBy("country").parquet("/data/output")
- C. df.write.mode("overwrite").parquet("/data/output")
- D. df.write.partitionBy("country").parquet("/data/output")
Answer: A
Explanation:
The.mode("overwrite")ensures that existing files at the path will be replaced.
partitionBy("country")optimizes queries by writing data into partitioned folders.
Correct syntax:
df.write.mode("overwrite").partitionBy("country").parquet("/data/output")
- Source:Spark SQL, DataFrames and Datasets Guide
NEW QUESTION # 55
A data engineer replaces the exact percentile() function with approx_percentile() to improve performance, but the results are drifting too far from expected values.
Which change should be made to solve the issue?
- A. Increase the value of the accuracy parameter in order to increase the memory usage but also improve the accuracy
- B. Decrease the value of the accuracy parameter in order to decrease the memory usage but also improve the accuracy
- C. Increase the last value of the percentage parameter to increase the accuracy of the percentile ranges
- D. Decrease the first value of the percentage parameter to increase the accuracy of the percentile ranges
Answer: A
Explanation:
The approx_percentile function in Spark is a performance-optimized alternative to percentile. It takes an optional accuracy parameter:
approx_percentile(column, percentage, accuracy)
Higher accuracy values → more precise results, but increased memory/computation.
Lower values → faster but less accurate.
From the documentation:
"Increasing the accuracy improves precision but increases memory usage." Final answer: D
NEW QUESTION # 56
A data engineer writes the following code to join two DataFramesdf1anddf2:
df1 = spark.read.csv("sales_data.csv") # ~10 GB
df2 = spark.read.csv("product_data.csv") # ~8 MB
result = df1.join(df2, df1.product_id == df2.product_id)
Which join strategy will Spark use?
- A. Shuffle join, because AQE is not enabled, and Spark uses a static query plan
- B. Shuffle join, as the size difference between df1 and df2 is too large for a broadcast join to work efficiently
- C. Broadcast join, as df2 is smaller than the default broadcast threshold
- D. Shuffle join because no broadcast hints were provided
Answer: C
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
The default broadcast join threshold in Spark is:
spark.sql.autoBroadcastJoinThreshold = 10MB
Sincedf2is only 8 MB (less than 10 MB), Spark will automatically apply a broadcast join without requiring explicit hints.
From the Spark documentation:
"If one side of the join is smaller than the broadcast threshold, Spark will automatically broadcast it to all executors." A is incorrect because Spark does support auto broadcast even with static plans.
B is correct: Spark will automatically broadcast df2.
C and D are incorrect because Spark's default logic handles this optimization.
Final Answer: B
NEW QUESTION # 57
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
- A. Execute their pyspark shell with the option--remote "sc://localhost"
- B. Execute their pyspark shell with the option--remote "https://localhost"
- C. Ensure the Spark propertyspark.connect.grpc.binding.portis set to 15002 in the application code
- D. Add.remote("sc://localhost")to their SparkSession.builder calls in their Spark code
- E. Set the environment variableSPARK_REMOTE="sc://localhost"before starting the pyspark shell
Answer: A,E
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
Spark Connect enables decoupling of the client and Spark driver processes, allowing remote access. Spark supports configuring the remote Spark Connect server in multiple ways:
From Databricks and Spark documentation:
Option B (--remote "sc://localhost") is a valid command-line argument for thepysparkshell to connect using Spark Connect.
Option C (settingSPARK_REMOTEenvironment variable) is also a supported method to configure the remote endpoint.
Option A is incorrect because Spark Connect uses thesc://protocol, nothttps://.
Option D requires modifying the code, which the question explicitly avoids.
Option E configures the port on the server side but doesn't start a client connection.
Final Answers: B and C
NEW QUESTION # 58
A DataFramedfhas columnsname,age, andsalary. The developer needs to sort the DataFrame byagein ascending order andsalaryin descending order.
Which code snippet meets the requirement of the developer?
- A. df.sort("age", "salary", ascending=[False, True]).show()
- B. df.sort("age", "salary", ascending=[True, True]).show()
- C. df.orderBy("age", "salary", ascending=[True, False]).show()
- D. df.orderBy(col("age").asc(), col("salary").asc()).show()
Answer: C
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
To sort a PySpark DataFrame by multiple columns with mixed sort directions, the correct usage is:
python
CopyEdit
df.orderBy("age","salary", ascending=[True,False])
agewill be sorted in ascending order
salarywill be sorted in descending order
TheorderBy()andsort()methods in PySpark accept a list of booleans to specify the sort direction for each column.
Documentation Reference:PySpark API - DataFrame.orderBy
NEW QUESTION # 59
A Data Analyst is working on the DataFrame sensor_df, which contains two columns:
Which code fragment returns a DataFrame that splits the record column into separate columns and has one array item per row?
A)
B)
C)
D)
- A. exploded_df = exploded_df.select(
"record_datetime",
"record_exploded.sensor_id",
"record_exploded.status",
"record_exploded.health"
)
exploded_df = sensor_df.withColumn("record_exploded", explode("record")) - B. exploded_df = sensor_df.withColumn("record_exploded", explode("record")) exploded_df = exploded_df.select("record_datetime", "sensor_id", "status", "health")
- C. exploded_df = exploded_df.select(
"record_datetime",
"record_exploded.sensor_id",
"record_exploded.status",
"record_exploded.health"
)
exploded_df = sensor_df.withColumn("record_exploded", explode("record")) - D. exploded_df = exploded_df.select("record_datetime", "record_exploded")
Answer: A
Explanation:
To flatten an array of structs into individual rows and access fields within each struct, you must:
Use explode() to expand the array so each struct becomes its own row.
Access the struct fields via dot notation (e.g., record_exploded.sensor_id).
Option C does exactly that:
First, explode the record array column into a new column record_exploded.
Then, access fields of the struct using the dot syntax in select.
This is standard practice in PySpark for nested data transformation.
Final answer: C
NEW QUESTION # 60
19 of 55.
A Spark developer wants to improve the performance of an existing PySpark UDF that runs a hash function not available in the standard Spark functions library.
The existing UDF code is:
import hashlib
from pyspark.sql.types import StringType
def shake_256(raw):
return hashlib.shake_256(raw.encode()).hexdigest(20)
shake_256_udf = udf(shake_256, StringType())
The developer replaces this UDF with a Pandas UDF for better performance:
@pandas_udf(StringType())
def shake_256(raw: str) -> str:
return hashlib.shake_256(raw.encode()).hexdigest(20)
However, the developer receives this error:
TypeError: Unsupported signature: (raw: str) -> str
What should the signature of the shake_256() function be changed to in order to fix this error?
- A. def shake_256(raw: str) -> str:
- B. def shake_256(raw: [str]) -> [str]:
- C. def shake_256(raw: [pd.Series]) -> pd.Series:
- D. def shake_256(raw: pd.Series) -> pd.Series:
Answer: D
Explanation:
Pandas UDFs (vectorized UDFs) process entire Pandas Series objects, not scalar values. Each invocation operates on a column (Series) rather than a single value.
Correct syntax:
@pandas_udf(StringType())
def shake_256(raw: pd.Series) -> pd.Series:
return raw.apply(lambda x: hashlib.shake_256(x.encode()).hexdigest(20)) This allows Spark to apply the function in a vectorized way, improving performance significantly over traditional Python UDFs.
Why the other options are incorrect:
A/D: These define scalar functions - not compatible with Pandas UDFs.
B: Uses an invalid type hint [pd.Series] (not a valid Python type annotation).
Reference:
PySpark Pandas API - @pandas_udf decorator and function signatures.
Databricks Exam Guide (June 2025): Section "Using Pandas API on Apache Spark" - creating and invoking Pandas UDFs.
NEW QUESTION # 61
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
- A. Use the command spark-submit with the -verbose flag to print the logs to the console.
- B. Fetch the logs by running a Spark job with the spark-sql CLI tool.
- C. Use the Spark UI to select the stage and view the executor logs directly from the stages tab.
- D. Locate the executor logs on the Spark master node, typically under the /tmp directory.
Answer: C
Explanation:
The Spark UI is the standard and most effective way to inspect executor logs, task time, input size, and shuffles.
From the Databricks documentation:
"You can monitor job execution via the Spark Web UI. It includes detailed logs and metrics, including task-level execution time, shuffle reads/writes, and executor memory usage." (Source: Databricks Spark Monitoring Guide) Option A is incorrect: logs are not guaranteed to be in /tmp, especially in cloud environments.
B . -verbose helps during job submission but doesn't give detailed executor logs.
D . spark-sql is a CLI tool for running queries, not for inspecting logs.
Hence, the correct method is using the Spark UI → Stages tab → Executor logs.
NEW QUESTION # 62
A developer notices that all the post-shuffle partitions in a dataset are smaller than the value set for spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold.
Which type of join will Adaptive Query Execution (AQE) choose in this case?
- A. A sort-merge join
- B. A broadcast nested loop join
- C. A shuffled hash join
- D. A Cartesian join
Answer: C
Explanation:
Adaptive Query Execution (AQE) dynamically selects join strategies based on actual data sizes at runtime. If the size of post-shuffle partitions is below the threshold set by:
spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
then Spark prefers to use a shuffled hash join.
From the Spark documentation:
"AQE selects a shuffled hash join when the size of post-shuffle data is small enough to fit within the configured threshold, avoiding more expensive sort-merge joins." Therefore:
A is wrong - Cartesian joins are only used with no join condition.
B is correct - this is the optimized join for small partitioned shuffle data under AQE.
C and D are used under other scenarios but not for this case.
Final answer: B
NEW QUESTION # 63
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
- A. customerDF.withColumn("username", split(col("email"), "@").getItem(0)) \
.withColumn("domain", split(col("email"), "@").getItem(1)) - B. customerDF.withColumn("username", substring_index(col("email"), "@", 1)) \
.withColumn("domain", substring_index(col("email"), "@", -1)) - C. customerDF.select(
regexp_replace(col("email"), "@", "").alias("username"),
regexp_replace(col("email"), "@", "").alias("domain")
) - D. customerDF.select(
col("email").substr(0, 5).alias("username"),
col("email").substr(-5).alias("domain")
)
Answer: A
Explanation:
Option B is the correct and idiomatic approach in PySpark to split a string column (like email) based on a delimiter such as "@".
The split(col("email"), "@") function returns an array with two elements: username and domain.
getItem(0) retrieves the first part (username).
getItem(1) retrieves the second part (domain).
withColumn() is used to create new columns from the extracted values.
Example from official Databricks Spark documentation on splitting columns:
from pyspark.sql.functions import split, col
df.withColumn("username", split(col("email"), "@").getItem(0)) \
.withColumn("domain", split(col("email"), "@").getItem(1))
Why other options are incorrect:
A uses fixed substring indices (substr(0, 5)), which won't correctly extract usernames and domains of varying lengths.
C uses substring_index, which is available but less idiomatic for splitting emails and is slightly less readable.
D removes "@" from the email entirely, losing the separation between username and domain, and ends up duplicating values in both fields.
Therefore, Option B is the most accurate and reliable solution according to Apache Spark 3.5 best practices.
NEW QUESTION # 64
A developer is working with a pandas DataFrame containing user behavior data from a web application.
Which approach should be used for executing agroupByoperation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)
C)
D)
- A. Use theapplyInPandasAPI:
df.groupby("user_id").applyInPandas(mean_func, schema="user_id long, value double").show() - B. Use a Pandas UDF:
@pandas_udf("double")
def mean_func(value: pd.Series) -> float:
return value.mean()
df.groupby("user_id").agg(mean_func(df["value"])).show() - C. Use a regular Spark UDF:
from pyspark.sql.functions import mean
df.groupBy("user_id").agg(mean("value")).show() - D. Use themapInPandasAPI:
df.mapInPandas(mean_func, schema="user_id long, value double").show()
Answer: A
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
The correct approach to perform a parallelizedgroupByoperation across Spark worker nodes using Pandas API is viaapplyInPandas. This function enables grouped map operations using Pandas logic in a distributed Spark environment. It applies a user-defined function to each group of data represented as a Pandas DataFrame.
As per the Databricks documentation:
"applyInPandas()allows for vectorized operations on grouped data in Spark. It applies a user-defined function to each group of a DataFrame and outputs a new DataFrame. This is the recommended approach for using Pandas logic across grouped data with parallel execution." Option A is correct and achieves this parallel execution.
Option B (mapInPandas) applies to the entire DataFrame, not grouped operations.
Option C uses built-in aggregation functions, which are efficient but not customizable with Pandas logic.
Option D creates a scalar Pandas UDF which does not perform a group-wise transformation.
Therefore, to run agroupBywith parallel Pandas logic on Spark workers, Option A usingapplyInPandasis the only correct answer.
Reference: Apache Spark 3.5 Documentation # Pandas API on Spark # Grouped Map Pandas UDFs (applyInPandas)
NEW QUESTION # 65
A data scientist is analyzing a large dataset and has written a PySpark script that includes several transformations and actions on a DataFrame. The script ends with a collect() action to retrieve the results.
How does Apache Spark™'s execution hierarchy process the operations when the data scientist runs this script?
- A. The collect() action triggers a job, which is divided into stages at shuffle boundaries, and each stage is split into tasks that operate on individual data partitions.
- B. Spark creates a single task for each transformation and action in the script, and these tasks are grouped into stages and jobs based on their dependencies.
- C. The entire script is treated as a single job, which is then divided into multiple stages, and each stage is further divided into tasks based on data partitions.
- D. The script is first divided into multiple applications, then each application is split into jobs, stages, and finally tasks.
Answer: A
Explanation:
In Apache Spark, the execution hierarchy is structured as follows:
Application: The highest-level unit, representing the user program built on Spark.
Job: Triggered by an action (e.g., collect(), count()). Each action corresponds to a job.
Stage: A job is divided into stages based on shuffle boundaries. Each stage contains tasks that can be executed in parallel.
Task: The smallest unit of work, representing a single operation applied to a partition of the data.
When the collect() action is invoked, Spark initiates a job. This job is then divided into stages at points where data shuffling is required (i.e., wide transformations). Each stage comprises tasks that are distributed across the cluster's executors, operating on individual data partitions.
This hierarchical execution model allows Spark to efficiently process large-scale data by parallelizing tasks and optimizing resource utilization.
NEW QUESTION # 66
A data engineer is streaming data from Kafka and requires:
Minimal latency
Exactly-once processing guarantees
Which trigger mode should be used?
- A. .trigger(continuous=True)
- B. .trigger(availableNow=True)
- C. .trigger(continuous='1 second')
- D. .trigger(processingTime='1 second')
Answer: D
Explanation:
Exactly-once guarantees in Spark Structured Streaming require micro-batch mode (default), not continuous mode.
Continuous mode (.trigger(continuous=...)) only supports at-least-once semantics and lacks full fault-tolerance.
trigger(availableNow=True) is a batch-style trigger, not suited for low-latency streaming.
So:
Option A uses micro-batching with a tight trigger interval → minimal latency + exactly-once guarantee.
Final answer: A
NEW QUESTION # 67
A data engineer is working on the DataFrame: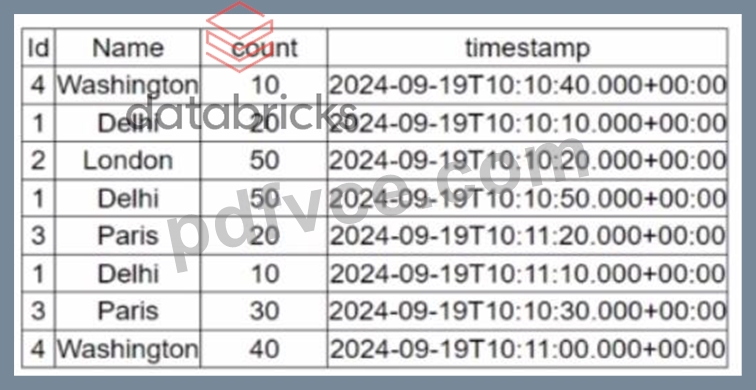
(Referring to the table image: it has columns Id, Name, count, and timestamp.) Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
- A. df.select("Name").distinct()
- B. df.select("Name").orderBy(df["Name"].asc())
- C. df.select("Name").distinct().orderBy(df["Name"])
- D. df.select("Name").distinct().orderBy(df["Name"].desc())
Answer: C
Explanation:
To extract unique values from a column and sort them alphabetically:
distinct() is required to remove duplicate values.
orderBy() is needed to sort the results alphabetically (ascending by default).
Correct code:
df.select("Name").distinct().orderBy(df["Name"])
This is directly aligned with standard DataFrame API usage in PySpark, as documented in the official Databricks Spark APIs. Option A is incorrect because it may not remove duplicates. Option C omits sorting. Option D sorts in descending order, which doesn't meet the requirement for alphabetical (ascending) order.
NEW QUESTION # 68
A Data Analyst needs to retrieve employees with 5 or more years of tenure.
Which code snippet filters and shows the list?
- A. employees_df.filter(employees_df.tenure >= 5).collect()
- B. employees_df.where(employees_df.tenure >= 5)
- C. employees_df.filter(employees_df.tenure >= 5).show()
- D. filter(employees_df.tenure >= 5)
Answer: C
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
To filter rows based on a condition and display them in Spark, usefilter(...).show():
employees_df.filter(employees_df.tenure >= 5).show()
Option A is correct and shows the results.
Option B filters but doesn't display them.
Option C uses Python's built-infilter, not Spark.
Option D collects the results to the driver, which is unnecessary if.show()is sufficient.
Final Answer: A
NEW QUESTION # 69
What is the behavior for function date_sub(start, days) if a negative value is passed into the days parameter?
- A. The number of days specified will be added to the start date
- B. The number of days specified will be removed from the start date
- C. An error message of an invalid parameter will be returned
- D. The same start date will be returned
Answer: A
Explanation:
The function date_sub(start, days) subtracts the number of days from the start date. If a negative number is passed, the behavior becomes a date addition.
Example:
SELECT date_sub('2024-05-01', -5)
-- Returns: 2024-05-06
So, a negative value effectively adds the absolute number of days to the date.
NEW QUESTION # 70
A data analyst builds a Spark application to analyze finance data and performs the following operations:filter, select,groupBy, andcoalesce.
Which operation results in a shuffle?
- A. coalesce
- B. select
- C. groupBy
- D. filter
Answer: C
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
ThegroupBy()operation causes a shuffle because it requires all values for a specific key to be brought together, which may involve moving data across partitions.
In contrast:
filter()andselect()are narrow transformations and do not cause shuffles.
coalesce()tries to reduce the number of partitions and avoids shuffling by moving data to fewer partitions without a full shuffle (unlikerepartition()).
Reference:Apache Spark - Understanding Shuffle
NEW QUESTION # 71
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
- A. The Spark engine optimizes the execution plan during the transformations, causing delays.
- B. The Spark engine requires manual intervention to start executing transformations.
- C. Transformations are evaluated lazily.
- D. Transformations are executed immediately to build the lineage graph.
- E. Only actions trigger the execution of the transformation pipeline.
Answer: C,E
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
Apache Spark employs a lazy evaluation model for transformations. This means that when transformations (e.
g.,map(),filter()) are applied to a DataFrame, Spark does not execute them immediately. Instead, it builds a logical plan (lineage) of transformations to be applied.
Execution is deferred until an action (e.g.,collect(),count(),save()) is called. At that point, Spark's Catalyst optimizer analyzes the logical plan, optimizes it, and then executes the physical plan to produce the result.
This lazy evaluation strategy allows Spark to optimize the execution plan, minimize data shuffling, and improve overall performance by reducing unnecessary computations.
NEW QUESTION # 72
18 of 55.
An engineer has two DataFrames - df1 (small) and df2 (large). To optimize the join, the engineer uses a broadcast join:
from pyspark.sql.functions import broadcast
df_result = df2.join(broadcast(df1), on="id", how="inner")
What is the purpose of using broadcast() in this scenario?
- A. It reduces the number of shuffle operations by replicating the smaller DataFrame to all nodes.
- B. It ensures that the join happens only when the id values are identical.
- C. It filters the id values before performing the join.
- D. It increases the partition size for df1 and df2.
Answer: A
Explanation:
A broadcast join is a type of join where the smaller DataFrame is replicated (broadcast) to all worker nodes in the cluster. This avoids shuffling the large DataFrame across the network.
Benefits:
Eliminates shuffle for the smaller dataset.
Greatly improves performance when one side of the join is small enough to fit in memory.
Correct usage example:
df_result = df2.join(broadcast(df1), "id")
This is a map-side join, where each executor joins its local partition of the large dataset with the broadcasted copy of the small one.
Why the other options are incorrect:
A: Broadcasting does not change partition sizes.
B: Joins always match on key equality; this is not specific to broadcast joins.
D: Broadcasting does not filter; it distributes data for faster joins.
Reference:
Databricks Exam Guide (June 2025): Section "Developing Apache Spark DataFrame/DataSet API Applications" - broadcast joins and partitioning strategies.
PySpark SQL Functions - broadcast() method documentation.
NEW QUESTION # 73
......
Study HIGH Quality Associate-Developer-Apache-Spark-3.5 Free Study Guides and Exams Tutorials: https://topexamcollection.pdfvce.com/Databricks/Associate-Developer-Apache-Spark-3.5-exam-pdf-dumps.html